Learning from Demonstration
Having engineers program behavior for robots in each specific application across factories, hospitals, and households is intractable, can result in suboptimal robot policies, and may require access to domain information that is private. Thus, to truly achieve ubiquity of robotics, end-users must be able to interactively teach robots desired behaviors, thereby imparting their domain knowledge onto the robot.
However, here we face two issues, 1) users may provide stylized demonstrations leading to heterogeneity across collected demonstrations, and 2) users may provide suboptimal demonstrations due to the correspondence problem or being non-experts themselves.
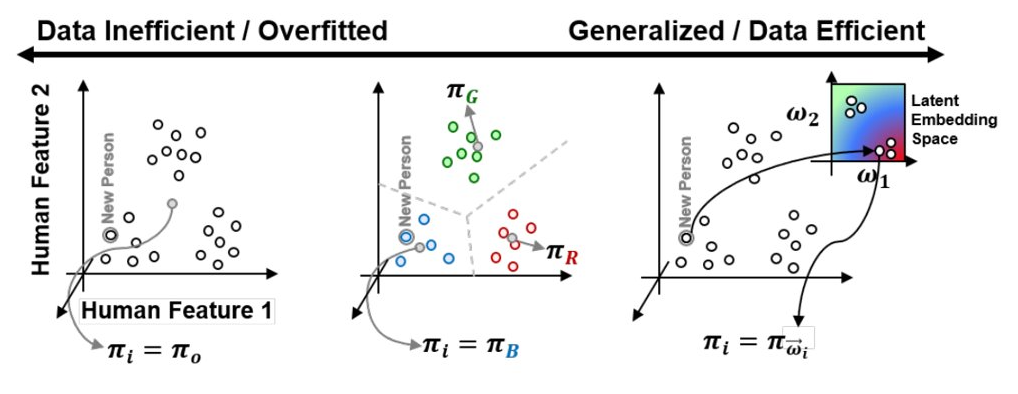
The challenge I pose is to develop new apprenticeship learning techniques for capturing these heterogeneous rules-of-thumb in order to scale beyond the power of a single expert. Such heterogeneity is not readily handled by traditional apprenticeship learning approaches that assume demonstrator homogeneity. A canonical example of this limitation is of human drivers teaching an autonomous car to pass a slower-moving car, where some drivers prefer to pass on the left and others on the right. Apprenticeship learning approaches assuming homogeneous demonstrations either fit the mean (i.e., driving straight into the car ahead) or fit a single mode (i.e., only pass to the left).
|
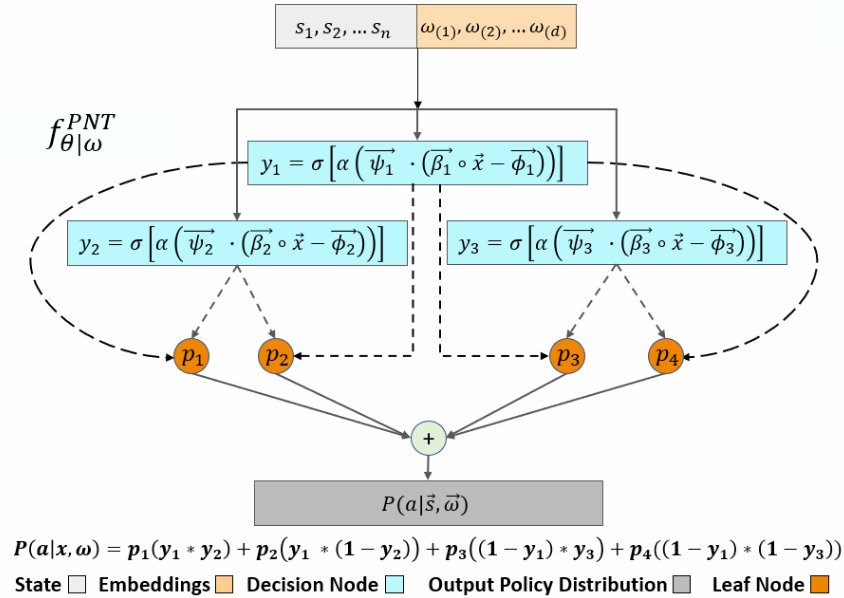
To effectively learn from heterogeneous decision-makers, I must capture the homo- and heterogeneity in their demonstrations, allowing us to learn a general behavior model accompanied by personalized embeddings that fit distinct behavior modalities. I contribute a novel apprenticeship learning model for resource scheduling, "Personalized Neural Trees", by extending DDTs in four important ways: 1) Personalized embeddings as a latent variable representing person-specific modality , 2) Variational inference mechanism to maximize the mutual information between the embedding and the modeled decision-maker , and 3) Counterfactual reasoning to increase data-efficiency, and 4) Novel feature selector for each decision node to enhance interpretability. |
Project materials:
- Talk from the NeurIPS'20.
-
Rohan Paleja, Andrew Silva, Letian Chen, andMatthew Gombolay. Interpretable and Personalized Apprenticeship Scheduling: Learning Interpretable Scheduling Policies from Heterogeneous User Demonstrations. Conference on Neural Information Processing Systems (NeurIPS), 2020.

For robotics, we utilize LfD frameworks with interaction. As such, to learn from heterogeneous demonstrations, we develop a novel Inverse Reinforcement Learning (IRL) algorithm, Multi-Strategy Reward Distillation (MSRD), that simultaneously infers the user's intent and decision-making policy by decomposing person-specific reward functions into a shared task reward and personalized strategy rewards via network distillation. MSRD has been shown to achieve accurate recovery of the task objective, represent demonstrator preferences, and produce versatile robot policies that resemble demonstrated strategies.
To address suboptimal demonstrations, in SSRR, we develop a novel IRL algorithm, Self-Supervised Reward Regression (SSRR) that is able to learn from suboptimal demonstration by characterizing the relationship between a policy’s performance and the amount of injected noise. We empirically find that we can infer an idealized reward function from suboptimal demonstration, outperform received suboptimal demonstrations by ~ 200\% in simulated domains, and greatly improve upon collected real-world robot demonstrations in a robot table-tennis setup.
Project materials:
-
Letian Chen, Rohan Paleja, Muyleng Ghuy, andMatthew Gombolay. Joint Goal and Strategy Inference across Heterogeneous Demonstrators via Reward Network Distillation. ACM/IEEE International Conference on Human Robot Interaction (HRI), 2020. -
Letian Chen, Rohan Paleja, andMatthew Gombolay. Learning from Suboptimal Demonstration via Self-Supervised Reward Regression. Conference on Robot Learning (CoRL), 2021.Best Paper Finalist.