Here, I present two multi-agent coordination algorithms that let decentralized robots learn
to collectively share knowledge and develop collaboration plans: Multi-agent Graph Attention
Communication (MAGIC) and Heterogeneous Policy Networks (HetNet).
Communication is a key component of successful coordination, enabling the
agents to convey
information and cooperate to collectively achieve shared goals. In high-performing human teams,
human
experts judiciously choose when to communicate and whom to communicate with, communicating only when
beneficial. We would like agents to emulate such behavior, without the need of hand-defining
communication protocols across agents.
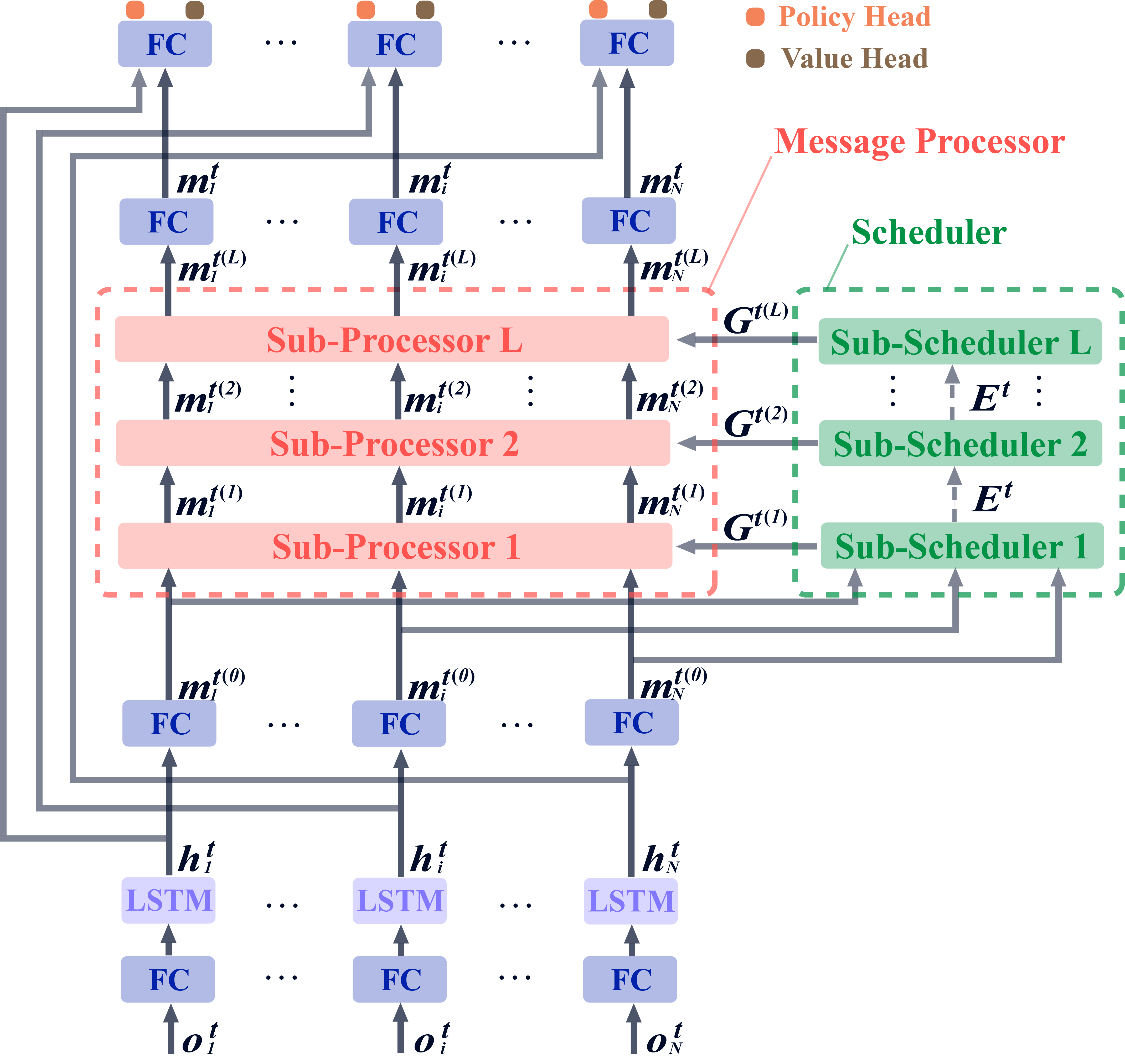
We propose a novel multi-agent reinforcement learning algorithm,
Multi-Agent Graph-attentIon Communication (MAGIC), with a
graph-attention communication protocol in which we learn 1) a
Scheduler to help with the problems of when to communicate and
whom to address messages to, and 2) a Message Processor
which integrates and processes
received messages in preparation for decision-making.
Figure 1: MAGIC Framework
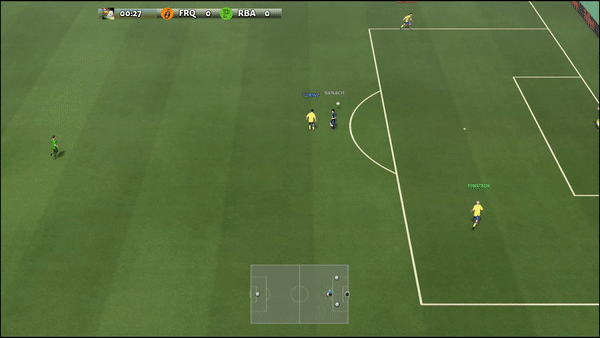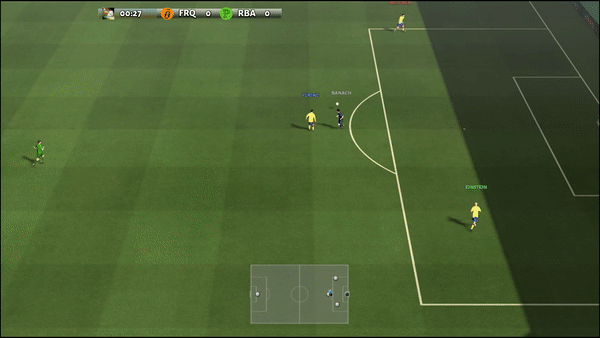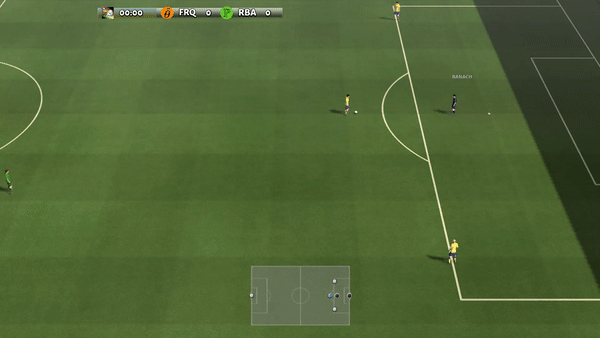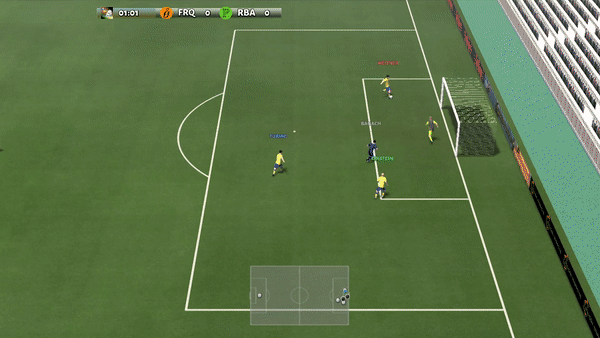
Figure 1: MAGIC in Google Research Football
We set a new state-of-the-art in communication-based
MARL by modeling the topology of
interactions among agents as a dynamic directed graph that accommodates time-varying communication
needs and accurately captures the relations between agents.
With Heterogeneous Policy Networks, we move to thinking about
"heterogeneous" robots. Heterogeneity in robots' design
characteristics and their roles are introduced to leverage the relative merits of different agents
and their capabilities (e.g., a ground robot vs. a UAV). We define a heterogeneous robot team as a
group of cooperative agents that are capable of performing different tasks and may have access to
different sensory information.
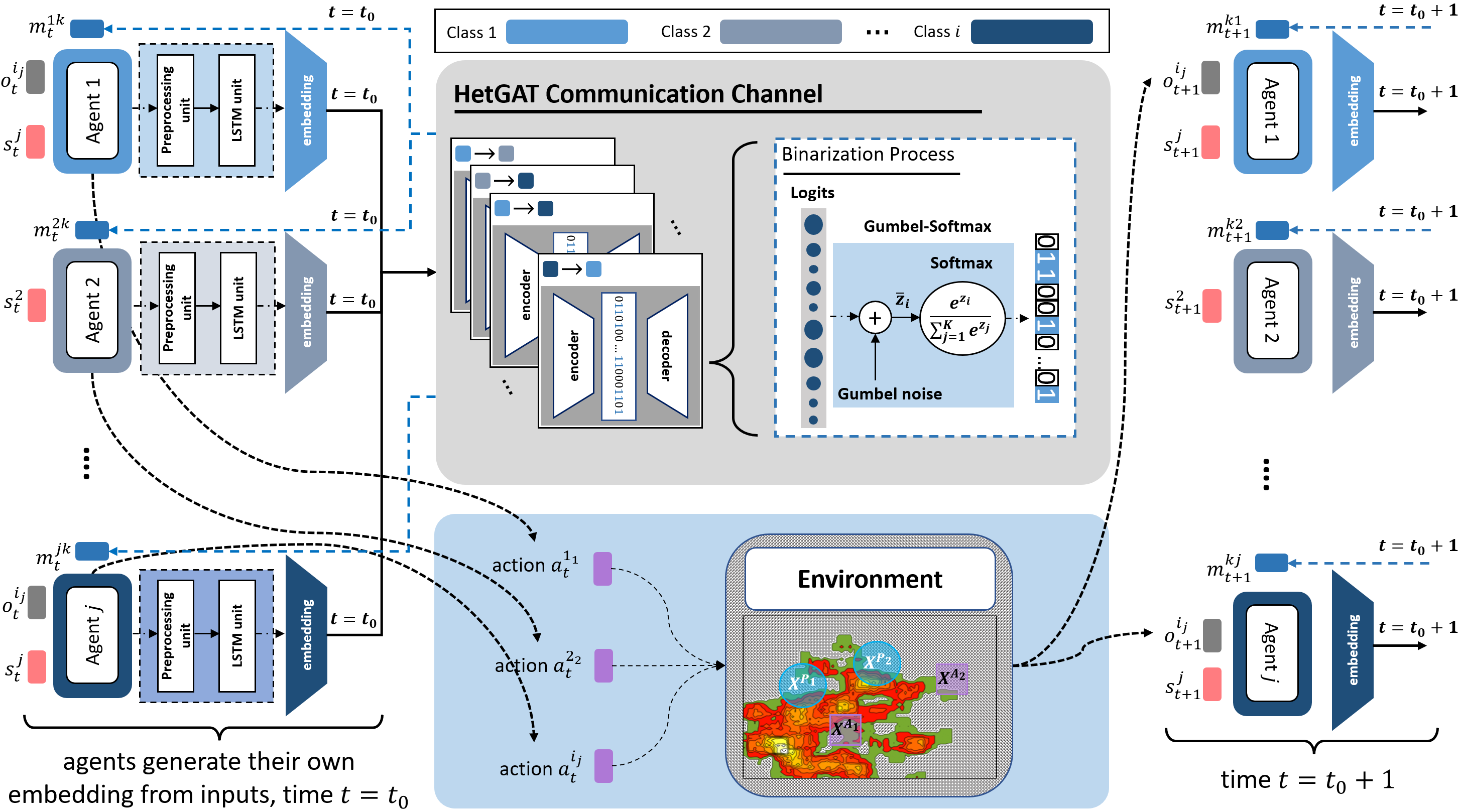
Figure 1: Heterogeneous Policy Networks
We categorize agents with similar state, action, and observation
spaces in the same class. In such a heterogeneous setting, communicating is not straightforward as
agents do not speak the same "language''; The dependency generated via sensor-lax agents on agents
with strong sensing capabilities makes efficient communication protocols for cooperation a
requirement rather than an additional modeling technique for performance.
Heterogeneous Policy Networks is an end-to-end model with a differentiable
encoder-decoder channel to account for the heterogeneity of inter-class messages, "translating''
the encoded messages into a shared, intermediate language among agents of a composite team. We can
now autonomously learn behaviors to coordinate multiple robots, varying in sensor
or actuator capabilities, to accomplish objectives that a single agent could not handle alone, such
as coordinating to detect and put out a fire!